안녕하세요! 😊 저는 BDA 학회에서 기계 학습(ML)과 데이터 전처리를 다루는 Pandas 수업을 수강 중이고,
데이터 분석 분야에 필수적인 SQLD 자격증 취득과정을 기록해보려고 합니다 📝
SQLD 자격증이 데이터 직무에서 기본적인 역량이라고 생각해서 학회 프로그램 중 하나인
SQLD 스터디에 참여하고 있습니다.
SQLD 스터디에서 진행하는 과제를 중심으로 1-2주차에 해당하는 내용들을 정리하고 복습해보겠습니다 !

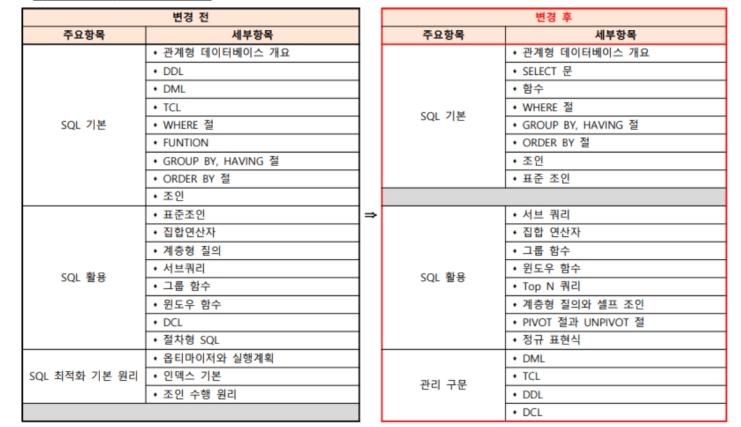
sqld 시험범위가 24년 개정이 되어서 이 개정표를 참고해서
정리해보도록 하겠습니다.
데이터 베이스란 ?
: 데이터(data)들의 모임(base)
- 여러 데이터들을 모아 통합적으로 관리하는 기술
- 여러 사람들이 함꼐 사용하고 공유할 수 있음
=> 데이터 베이스가 생기면서 데이터를 한 곳에 모아 저장하고 공유할 수 있게됨
데이터 모델이란 ?
: 현실세계의 대상을 추상화, 단순화, 명확화하여 데이터베이스로 표현
ex. 나만의 주택을 만든다고 해보자
단순한 집의 설계도를 그려볼거임 -> 화장실은 몇개, 기와집이였음 좋겠는 디테일한 설계도를 만들고
-> 실제로 집을 구축하는 과정 -> 완공
이걸 데이터 모델링으로 들고오면
요구 사항 접수 -> 개념적 데이터 모델링 -> 논리적 데이터 모델링 -> 물리적 데이터 모델링 -> 데이터베이스 저장할 수 있는 세팅 완료
데이터 모델링 특징
- 추상화
: 현실세계, 개념을 일정한 형식으로 '간단하게' 표현
- 단순화
: 현실세계를 '정해진 표기법'으로 단순하고 쉽게 표현, 핵심에 집중 + 불필요한 내용 제거
- 명확화
: 애매모호한 것들을 제거하고 ,'정확하게' 현상을 기술
데이터 모델링의 목적
- 단순히 DB 시스템을 구축하기 위한 것이 아닌 업무 설명 , 분석, 형상화 목적도 있음
- 분석된 모델로 실제 DB 생성하며 개발 및 데이터 관리에도 사용됨
엔터티란?
: 업무에 필요한 정보를 저장/ 관리하기 위한 집합적인 명사 개념
인스턴스란 ?
: 엔터티 집합 내에 존재하는 개별적인 대상
엔터티 특징
- 업무에서 쓰이는 정보이어야함
- 유일한 식별자가 있어야 함
- 2개 이상의 인스턴스를 가져야 함
- 반드시 속성을 가져야 함
- 즉 하나의 엔터티는 2개 이상의 속성을 가져야 함
- 관계가 1개 이상 존재함
엔터티 분류 방법과 종류
1. 유,무형에 따른 분류-> 개사유 ~
- 유형 엔터티 : 물리적 형태가 있는 엔터티 ex. 직원, 강사, 고객, 상품, 회원
- 개념 엔터티 : 물리적 형태가 없는 엔터티 ex. 부서, 학과, 직급
- 사건 엔터티 : 행위로 인해 발생하는 엔터티 ex. 주문, 이벤트, 강의, 매출
2. 발생시점에 따른 분류 -> 행기중 ~!
- 기본 엔터티 : 원래 존재하는 요소 -> 주식별자를 가짐 ex. 상품, 회원, 부서
- 중심 엔터티 : 업무 과정 중 하나, 기본 엔터티로부터 파생, 행위 엔터티 생성 ex. 주문, 매출,계약
- 행위 엔터티 : 2개 이상의 엔터티로부터 파생 ex. 주문 내역, 이벤트 응모 이력 등
엔터티의 명명규칙
- 가능한 협업 용어 사용 ex. 사람 -> 고객
- 가능하면 약어 사용 X, 영어는 대문자로
- 단수 명사 사용 ex. 직원들 -> 직원
- 엔터티의 이름은 유일해야 함
- 엔터티 생성의미대로 이름을 부여
속성이란?
: 업무상 관리하기 위해 의미적으로 더는 분리되지 않는 최소의 데이터 단위
엔터티, 인스턴스, 속성의 관계

- 하나의 엔터티는 2개 이상의 인스턴스르 가짐
- 하나의 엔터티는 2개 이상의 속성을 가짐
- 속성은 각 인스턴스를 설명해 줄 수 있음
- 하나의 속성에는 하나의 속성값만 들어감
속성의 분류 (특성에 따른 분류)
- 기본 속성 : 업무로부터 추출한 속성으로 제일 많이 발생
- 설계 속성 : 설계시 규칙화 등이 필요해 만든 속성 코드성이나 일련번호
- 파생 속성 : 다른 속성들로부터 계산/ 변형되어 만들어진 속성
구성 방식 (각 구성 및 엔터티와의 관계)에 따른 분류
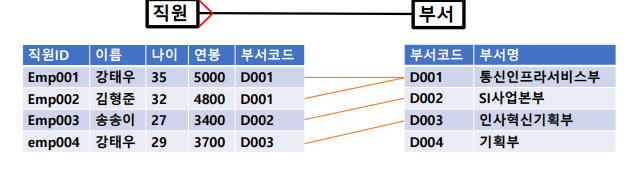
- PK 속성 , Primary Key : 일반 속성들의 종속성을 가진 키(기본키, 주식별자 키) #으로 표현 ex. 학번,사번
- FK 속성 : 다른 엔터티에서 가져온 속성(외래키), 다른 엔터티와의 관계를 맺게 해줌
- 일반속성 : PK, FK를 제외한 나머지 속성
-> 주 식별자에 있는 속성 FK가 될 수 있음 ex. #사원번호 (FK)
ex. 학과코드, 회원등급 코드,부서코드 -> 학과에 따른 따른 엔터티가 있는 것과 연결
| PK | 기본 |
| 설계 | 기본 |
| 부서코드 | 부서명 |
| D001 | 기획부 |
| D002 | 영업부 |
| D003 | 인사혁신기록부 |
| D004 | 통신인프라서비스부 |
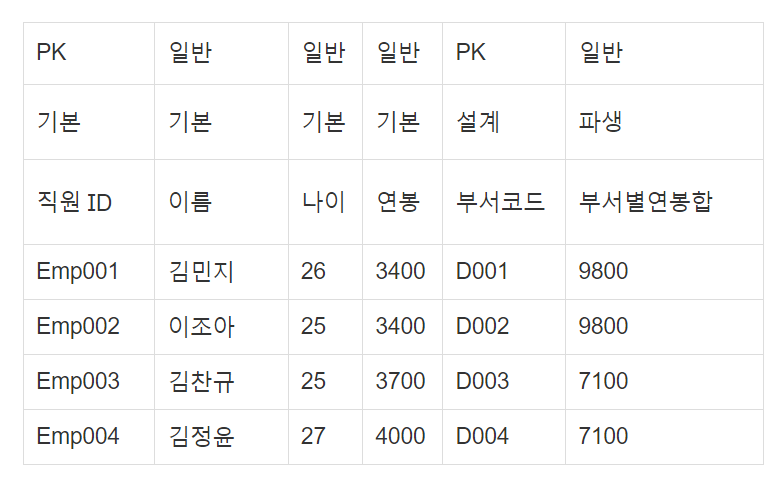
| PK | 일반 | 일반 | 일반 | PK | 일반 |
| 기본 | 기본 | 기본 | 기본 | 설계 | 파생 |
| 직원 ID | 이름 | 나이 | 연봉 | 부서코드 | 부서별연봉합 |
| Emp001 | 김민지 | 26 | 3400 | D001 | 9800 |
| Emp002 | 이조아 | 25 | 3400 | D002 | 9800 |
| Emp003 | 김찬규 | 25 | 3700 | D003 | 7100 |
| Emp004 | 김정윤 | 27 | 4000 | D004 | 7100 |
| PK/FK | 복합 |
| 직원ID | 주소 |
| Emp001 | 서울시 노원구 상계동 401호 |
| Emp002 | 창원시 성산구 성주동 1101호 |
| Emp003 | 창원시 성산구 성주동 1102호 |
| Emp004 | 서울시 송파구 아산동 1202호 |
속성 명명 규칙
- 가능한 현업 용어 사용
- 가능한 약어 사용 X
- 명사형을 사용하고 서술식이나 수식어 등을 제한하기
- 가능한 속성 이름은 전체 데이터 모델에서 유일해야 함
도메인이란?
: 각 속성이 입력 받을 수 있는 값의 정의 및 범위를 의미
보통 테이블을 만들 떄 속성마다 자료형 및 제약조건을 줄 떄 결정됨
- 나이는 숫자만 입력받을 수 있음.
입력값은 0~ 999까지로 함
- 이름은 문자형으로 입력받을 수 있음
최대 5자리만 받는걸로함
식별자 분류
- 대표성 여부 : 주식별자 VS 보조식별자
- 스스로 생성 여부 (자생여부) : 내부식별자 VS 외부식별자
- 단일속성 여부 : 단일식별자 VS 복합식별자
- 대체여부 : 본질식별자 VS 인조식별자
식별자란?
: 엔터티 내 유일한 인스턴스를 식별할 수 있는 속성의 집합
주식별자란?
: 주 식별자는 PK(Primary Key)에 해당하는 속성 -> PK는 여러개 존재할 수 있음
- 유일성 : 해당 속성이 인스턴스를 유일하게 식별할 수 있는 성질을 가졌는지
- 최소성 : 최소한의 속성들로만 유일성을 보장하게 하는지
- 불변성 : 속성값이 변하지 않아야 함
- 존재성 : 속성값은 NULL이 될 수 없음 , 값이 꼭 입력되어야 한다는 말
-> 유일성과 최소성을 만족하는 속성은 보조키로서 존재할 수 있음
-> 특정 특성을 만족함에 따라 속성은 특정 키로서 존재가능
주식별자 도출기준
- 업무에서 자주 쓰는 속성일 것
- 명칭, 이름 등은 피할 것
- 속성의 수가 많지 않을 것
보조식별자란?
: 인스턴스 식별은 가능하나 엔터티를 대표하는 식별자는 아님
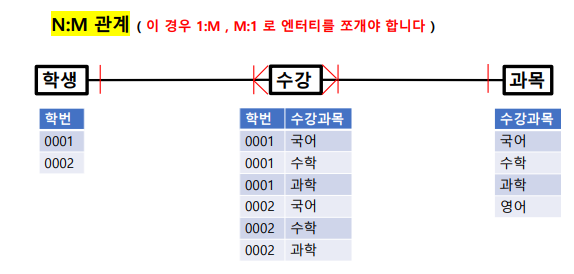
관계란?
: 엔터티 내의 인스턴스들 간에 서로 논리적인 연관성이 있는 상태
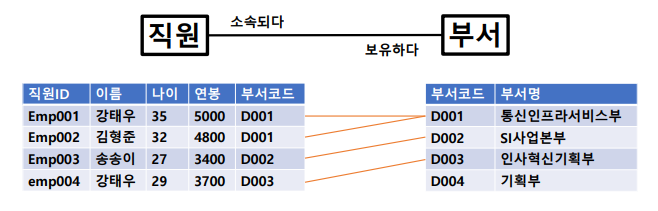
관계의 종류
- 존재 관계 : 모델링 된 엔터티 들이 존재로서 관계를 가짐
- 행위 관계 : 모델링 된 엔터티들이 행위에 의해 관계를 가짐
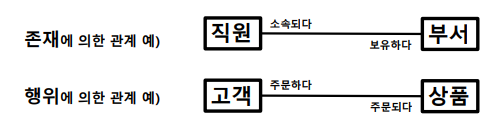
- ERD는 존재/행위 등 관계를 옆에 처럼 표시함
- UML 클래스 다이어그램
-> 연관관계 : 실선으로 표기
-> 의존관계 : 점선으로 표기
관계를 표시하는 방법
- IE 표기법
- Barker 표기법
관계명, 관계차수, 관계선택사항
1.관계명을 표시함. 이때 애매한 동사나 과거형을 피함 (IE, Barker 모두 표기방식은 같음)

2. 관계차수는 엔터티 내 각 인스터들이 얼마나 참여하는지를 의미 (1:1, 1:M, M:N)
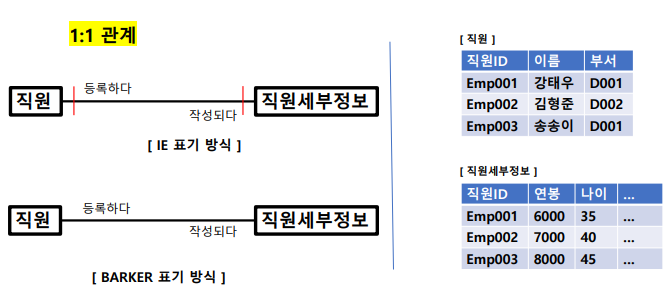
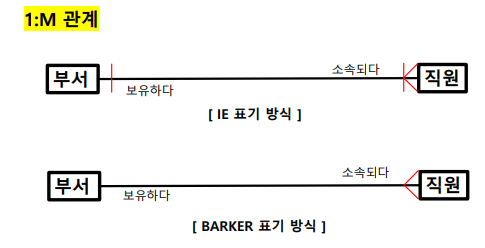
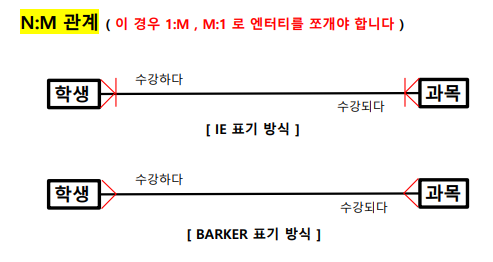
3. 관계선택사양은 엔터티 내 각 인스턴스들이 필수/ 선택 참여하는지를 의미함
관계 체크 사항
- 두 엔터티 사이에 관심 있는 연관규칙이 있는가?
- 두 엔터티 사이에 정보의 조합이 발생하는가?
- 업무기술서, 장표에 관계연결에 대한 규칙이 서술되었는가?
- 업무기술서, 장표에 관계연결을 가능케 하는 동사가 있는가?
데이터 모델링 3단계 (개념-논리-물리)
- 개념적 데이터 모델링 -> 논리적 데이터 모델링 -> 무리적 데이터 모델링
데이터베이스 3단계 구조
- 외부 (External) 스키마 : 여러 사용자 각각의 관점
- 개념 (Conceptual) 스키마 : 통합적, 조직 전체의 DB 관점
- 내부 (Internal) 스키마 : 데이터 물리 저장 구조 표현
정규화란 ?
: 데이터에 대한 중복을 제거하고 데이터가 관심사별로 처리되도록 엔터티를 쪼개 성능을 향상시키는 활동
-> 정규화 시 입력/ 삭제/수정 (DML)은 성능 향상 !, 조회는 성능이 향상 또는 저하될 수 도 있음
-> 논리 데이터 모델에서 행하는 과정임
정규화 과정 살펴보기
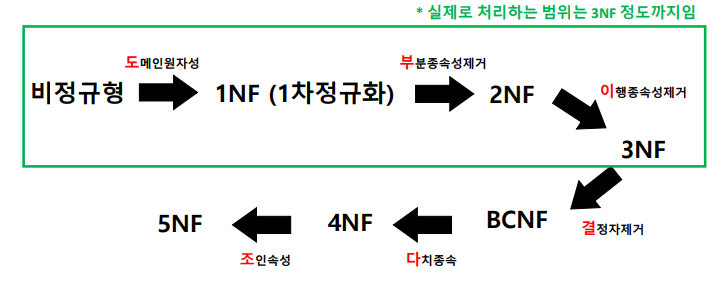
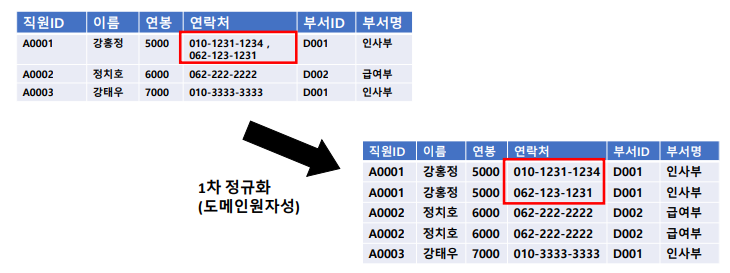
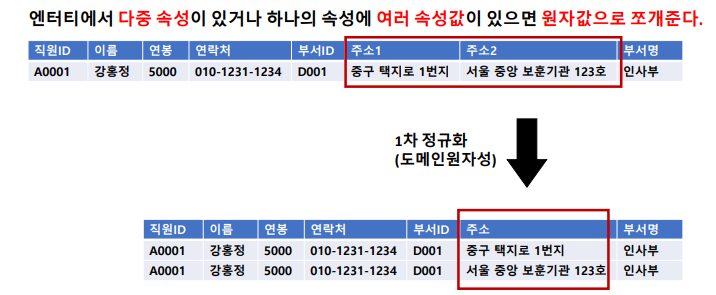
1차 정규화
: 엔터티에서 다중 속성이 있거나 하나의 속성에 여러 속성값이 있으면 원자값으로 쪼개줌
2차 정규화
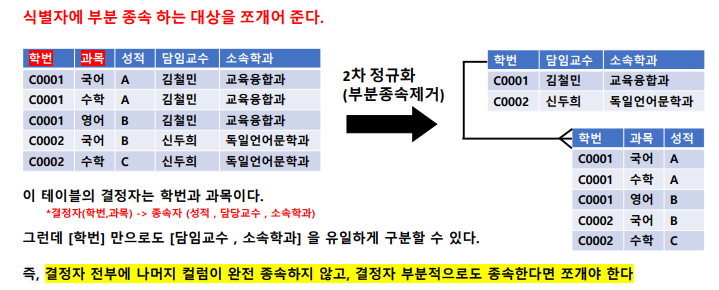
: 2차 정규화는 (1정규형 -> 2정규형 NF) 형태로 엔터티를 변경하는 활동임
3차 정규화
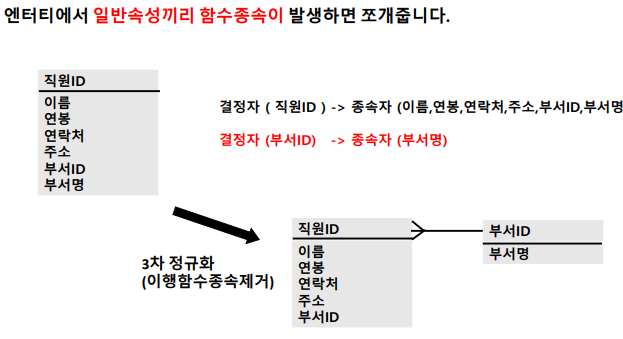
: 엔터티에서 일반속성끼리 함수종속이 발생하면 쪼개줌
반정규화 (=역정규화) < - 24년 시험부터는 빠지는데 정규화를 배웠으니까 반정규화도 한번 살펴보는정도로
: 정규화한 데이터를 다시 합쳐서 중복되게 하거나 통합, 분리 등을 수행하는 모델링 방식
- 테이블 반정규화 (테이블 병합, 테이블 분할, 테이블 추가 등)
- 컬럼 반정규화 (중복컬럼, 파생컬럼, 이력테이블 컬럼 추가 등)
- 관계 반정규화(중복관계 추가)
-> 칼럼 반정규화 - 중복 컬럼 추가 , 테이블에 중복되는 컬럼을 추가해 조인을 감소시킴
=> 무결성이 깨지는 일이 발생할 수도 있어서 반정규화는 사용을 잘 안함
그럼에도 불구하고 반정규화를 하는 경우
- 정규화를 통해 엔터티, 관계 수가 많아져서 조회 시 '조인'으로 인한 성능 저하가 예상될때
- 칼럼을 계산하고, 읽을 때 FK라서 여러 조인을 또 불러와서 성능이 저하될때
-> 즉, 조인으로 인한 I/O 양이 많아져서 처리 성능이 저하될때
-> 중복성을 증가시켜 조회 성능을 향상시킴
조인이란?
: 식별자를 상속해 이를 이용하여 데이터를 결합해 여러 엔터티에서 필요한 데이터를 한번에 가져오는 것
계층형 데이터 모델이란?
: 계층 구조를 가진 데이터를 저장한 모델 자긴 자신의 엔터티와 관계가 발생하는 경우
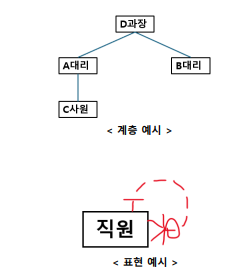
상호배타적 관계란 ?
: A와 B가 C 집단에 소속되었지만, 서로 공통적인 부분이 없는 관계
트랜잭션이란?
: 데이터베이스의 논리적인 연산 단위 혹은 논리적인 업무단위
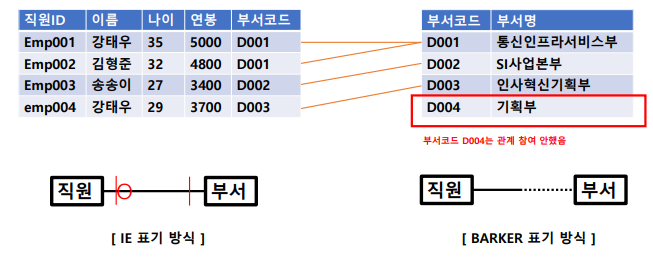
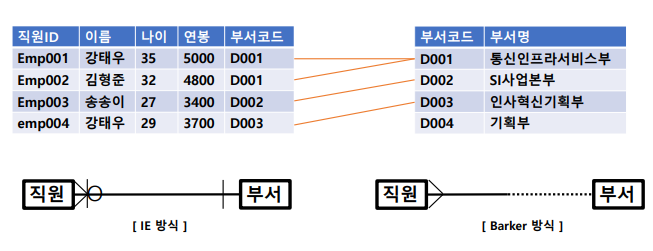
식별관계 VS 비식별관계
- 식별자 관계 : FK(외래키)가 PK(식별자)의 일부분인가?
- 비식별자 관계 : FK(외래키)가 PK(식별자)의 일부분이 아닌가?
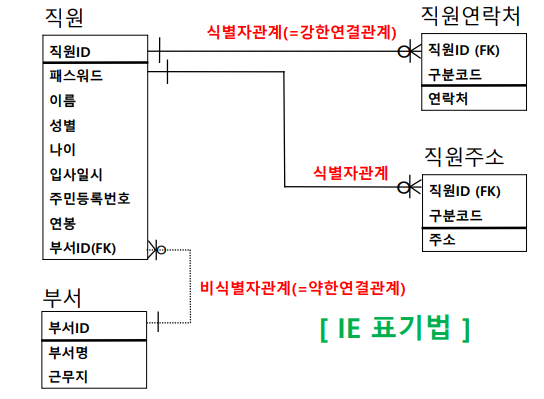
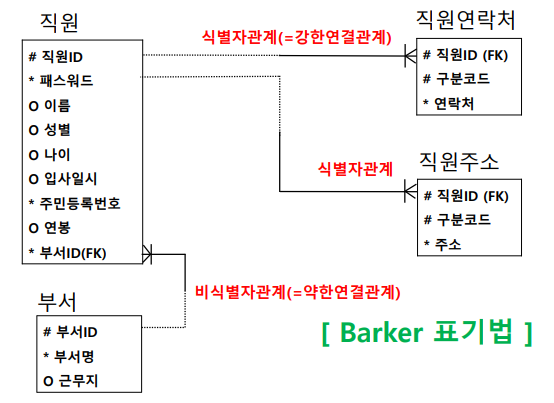
식별자 관계
: 부모 엔터티의 식별자 속성이 자식 엔터티의 주식별자가 되는 관계
- 강한 연결 관계
- 실선
- 부모 - 자식 관계가 항시 유지
비식별자 관계
: 부모 엔터티의 식별자 속성이 자식 엔터티의 일반 속성이 되는 관계
- 약한 연결 관계
- 점선 (선택적 연결)
- 부모 - 자식 관계가 유지 안될 수 있음
NULL 이란?
: 아직 정해지지 않은 값
NULL 이 필요한 이유
- 아직 어떤 값이 들어오지 않았음을 표현할 수 있음
- 테이블 (= 엔터티)의 특성상 행 X 열 형태를 유지해야 함
SQLD - 2과목
데이터베이스 관련 용어 정리
- 데이터베이스 (DataBase, DB)
: 데이터를 일정한 형태로 저장해놓은 것
- 데이터베이스관리시스템(DataBase Management System, DBMS)
: 기존 데이터베이스 기능에 추가로 데이터 손상을 방지 및 복구, 인증된 사용자만 접근 등 추가 기능을 지원하는
관리 시스템
- 관계형 DBMS (Relational DBMS, RDBMS)
: 테이블로 대이터를 관리하고 테이블간 관계를 이용해 데이터를 정의하는 방식으로 대부분의 기업이 사용하며
지금 공부하는 Oracle 도 RDBMS 중 하나임
- 테이블 (Table)
: RDBMS에서 실제 데이터가 저장되고 조회되는 2차원 배열 형태의 저장소 공간
: 엔터티, 속성, 인스턴스가 각각 DB가 이해할 수 있는 형태인 테이블, 컬럼, 튜플로 변경된 것
- SQL (Structured Query Language)
: RDBMS에서 데이터 정의, 조작, 조회, 제어 등을 하기 위해 사용되는 언어

SELECT란?
: 테이블에서 원하는 데이터를 조회할 때 사용하는 문법
SELECT * FROM TB_PRD;
- TB_PRD 테이블의 모든 컬럼 정보를 출력함
- * (애프터리스크)는 SELECT 뒤에 사용되며 테이블 내의 모든 컬럼 정보를 출력함
SELECT DISTINCT PRD_TYPE FROM TB_PRD ;
- TB_PRD 테이블의 PRD_TYPE 컬럼을 기준으로 값을 중복없이 출력함
- DISTINCT는 SELECT 뒤, 컬럼 앞에 사용되며 해당 컬럼 정보에 대해 중복을 제거함
AS는 SELECT 부분에서 출력하려는 컬럼에 대해 새로운 별명 (ALIAS)를 부여할 수 있음
AS 사용 시 주의사항
- 띄어쓰기 불가
- 문자로 시작
- 예약어 불가
- 특수문자는 $ , _ , # 만 가능함
SELECT에서 사칙연산하기
SELECT에서 연결연산 ( || 기호 사용하기 )
함수
: 함수는 입력 값을 넣어 특정한 기능을 통해 결과 값을 출력함
함수의 특징
- 블랙 박스가 어떻게 (how) 만들어져 있는지는 알 필요 없음
- 입력 개수와 출력 개수는 함수를 만든 사람의 마음
- 원하는 함수를 사용하고 싶다면 입력 개수, 출력 개수, 기능(what)만 알면 됨
내장형(built- in) 함수
:내장형 함수란 미리 만들어 놓은 함수

문자형 함수 : UPPER,SUBSTR,TRIM,REPLACE
1.UPPER
- 기능 : 입력받은 문자열에서 소문자를 대문자로 바꿔줌
select upper('abcde123@@@') as upper
from dual:2. SUBSTR (문자열, 시작점,[길이])
- 기능 : 입력받은 문자형 리터럴에서 시작위치에서 길이만큼 잘라낸다
- 0부터 시작 X , 1부터 시작임 !
3. TRIM
기능 : 입력받은 문자형 리터럴의 양 끝의 공백을 제거함 (단, 문자 중간의 공백은 제거 X)
SELECT TRIM(' 안녕하세요'), TRIM (' 안 녕 하 세요 ')
FROM DUAL;
4.REPLACE (문자열, 찾는 문자열,[변경 할 문자열])
기능 : 입력받은 문자형 리터럴 안에있는 바뀔값을 바꿀값으로 변경하여 출력
-> 변경 할 문자 입력 안하면 없애는 특징을 가짐
숫자형 함수 : ROUND (수, 자리수)
기능 : 실수를 소수점 자릿수까지 반올림한 결과를 출력함 (~까지)
select round (1.452,2), round(1.452,1)
from dual
날짜형 함수 : SYSDATE (SQL SERVER는 GETDATE() 이용)
기능 : 현재의 연,월,일,시,분,초를 반환
select sysdate
from dualselect getdate(); ### sql server 버전
형 변환 우 선순위 : 날짜형 > 숫자형 > 문자형
NULL은 정상적인 산술, 비교 연산 등이 불가능함
select 3 + null from dual
### 정답은? 3/null/3null/오류 = null
NULL 함수란 NULL 값을 대체할 수 있는 함수임
- NVL (data1, data2)
- DECODE (data1, data2,data3,data4)
- COALESCE(data1, data2,data3,...., dataN)
NVL(data1, data2)
- 내장형 함수
- 입력값을 두개 입력 받음
- data1에 null 값이 들어오면 data2를 출력하고 null이 아니면 data1를 출력함
DECODE(data1, data2,data3, data4 ,,....)
- data 1과 data2가 같으면 data 3을 출력하고 같지 않으면 data4를 출력함
WHERE절
: where절을 이용하면 원하는 행만 필터링해서 출력가능함
select cust_ID ### 3번째로 select 실행
, cust_name
, birth_by
from tb_cust ### 1번으로 실행됨
where money = 10000; ### 2번으로 실행됨. 조건에 맞는 친구들만 가져옴
비교 조건 = , =< , > 등으로 비교하는 조건
논리조건은 AND, OR으로 추가적인 조건을 줌
- AND : ~ 이고, 두가지 조건을 만족해야 출력됨
- OR : 또는 , 두가지 조건 중 하나만 맞아도 출력됨
부정 연산은 조건에 NOT 개념이 붙은 거
select *
from tb_prd
where not prd_type = '가전'
select *
from tb_prd
where prd_type != '가전'
NULL 연산은 IS NULL / IS NOT NULL 로 출력 가능함
: null은 산술 비교가 불가능이라 그냥 = null 이렇게 하면 출력이 안되고 is null 이라고 하면 출력 가능함
SQL 연산자 : IN ,BETWEEN , LIKE
select *
from TB_PRD
where PRD_TYPE IN ('가전','욕실용품', '스마트폰'); ## 타입이 가전이거나 욕실용품이거나 스마트폰인거
NOT IN 연산자 뒤에 입력된 조건들을 제외한 대상을 출력해줌
select *
from TB_PRD
where PRD_TYPE NOT IN ('가전','욕실용품','스마트폰');
BETWEEN 연산자는 범위조건 연산자임
select *
from TB_CUST
where act_point between 100 and 1000;
LIKE는 매칭 연산을 할 수 있음
- '수%' : 수를 포함하는 모든 정보 출력
- '%용%' : 용이 포함되는 모든 정보 출력
- '%기' : 기로 끝나는 모든 정보 출력
- '_ _ 기 ' : 앞에 두개의 문자만 들어가는 기로 끝나는 정보 출력
GROUP BY 문법을 이용하면 집계를 할 수 있음
- 특정 컬럼 (표현식)을 기준으로 튜플(행)을 그룹화 (=묶어서)하여 각각 단일행으로 표현
- 실제로 출력되는 튜플(행)이 감소함
- 따라서 입력할 수 있는 컬럼이 제한됨
- 대신 집계함수로 처리한 컬럼은 having, order by, select에도 입력이 가능함
HAVING 문법
- 집계가 완료된 대상을 필터링하는 문법
- 집계함수에 대해 조건을 줄 수 있음
- where절에서는 집계함수를 사용할 수 없음
- where절에서는 집계함수를 사용하지 못하는 이유 - where절은 groupby보다 먼저 실행됨
select 학생 ID, AVG (성적) AS 수학제외한 평균 ###5번
from 성적표 ### 1번
where 과목 != '수학' ### 2번
group by 학생 ID ### 3번
having avg(성적) <= 75 ### 4번
ORDER BY
- 데이터를 오름차순/ 내림차순으로 정렬
- 기본값이 ASC
- DESC는 내림차순
- 여러 컬럼 사용 가능
- 컬럼 이름 외에 AS 명칭이나 숫자로도 표현이 가능
1-2주차에 해당하는 내용은 여기까지였습니다.
SQLD가 제가 준비하는 두번째 자격증이여서 그런지 여러 후기들도 많이 찾아보고
SQL이 처음이여서 걱정도 많았는데 어떤 후기에서 합격했지만 한번더 준비해야한다면
이기적으로 준비할 것 이라는 글을 보고 확신을 했고
SQL은 처음이라 이기적 유튜브를 통해 강의랑 함께 공부하니까
훨씬 더 이해가 잘 되었어요 :)