from selenium import webdriver
browser = webdriver.Chrome()
keyword = input('찾고자하는 논문 주제를 입력하세요요')
url = f'https://www.dbpia.co.kr/search/topSearch?searchOption=all&query={keyword}'
# 여기에 keyword 넣으면 내가 키워드 입력한 곳으로 감
url = '' 이렇게 넣어도됨
browser.get(url)
🔹 헷갈리던 용어 정리 !
구문의미예시
find_element
하나만 찾음 (처음 하나만 반환)
browser.find_element(By.CLASS_NAME, 'title')
find_elements
여러 개를 리스트로 반환
browser.find_elements(By.CLASS_NAME, 'title')
.text
element 안의 텍스트 추출
title.text
.get_attribute('href')
링크 등 속성 값 추출
a_tag.get_attribute('href')
🔹 “구조 안의 구조” ?
HTML 문서는계층적 구조로 되어 있어요. 예를 들어, 하나의 논문(thesisCard) 안에 제목, 저자, 발행일 등 여러 정보가 포함되어 있죠.
데이터 타입을 적절히 변환합니다. 예) ID는 고유 값이니 문자열(str)로, 날짜 데이터는 pd.to_datetime()을 이용해 날짜 형식으로 변환
info() 함수로 데이터 타입이 잘 변환됐는지 확인합니다.
결측치가 있는지 info()나 isnull()로 확인 후, dropna()로 제거합니다.
전처리 후 head() 함수로 최종 데이터 형태를 다시 확인합니다.
3번에 만들었던 질문에서 필요한 데이터가 있다면 기존컬럼들을 이용하여 새로운 컬럼 만들기
ex. id와 같은 값은 고유한 값으로 str로 바꿔주기 / date는 날짜 형식이기 때문에 날짜로 바꿔주기
이때 pandas에서 날짜로 바꿔주는 함수는 to_datetime
데이터 타입 변경할건 변경하기
data['release_date'] = pd.to_datetime(data['release_date'], format='%Y-%m-%d') #년-월-일이였으니까 포맷을 맞춰서
대신 요로캐 포맷은 맞춰줘야함
info() 함수를 통해 데이터 타입 잘 변환되었는지 확인하기
한번더 info()함수를 불러와 결측치 확인하기
dropna()함수를 통해서 결측치 제거하기
데이터 가공을 다했으면 head()함수로 전처리 준비가 완료되었는지 확인하기
5. 분석 및 시각화
plotly 라이브러리 등의 시각화 도구로 그래프를 그려 분석 결과를 시각화합니다.
import plotly.express as px /// plotly 불러오는 방법
#plotly line data 불러오는 방법
fig = px.line(data_frame=your_dataframe, x="x_column_name", y="y_column_name")
fig.show()
///주의할점이 dataframe이 아니라 data_frame 인거 체크하기
# 1. title(영화 제목)별로 revenue(수익)를 그룹화하여 합계를 계산하고, 결과를 데이터프레임 형태로 정리
top = data.groupby('title')['revenue'].sum().reset_index()
/// .sum()이 아니라 mean() 도 가능함
# 2. 수익 기준으로 내림차순 정렬해서 가장 수익이 높은 순서대로 정렬
top = top.sort_values('revenue', ascending=False)
# 3. 상위 10개의 영화만 추출 (흥행 수익 TOP 10)
top = top.head(10)
# 4. Plotly의 bar 차트 생성
fig = px.bar(
data_frame=top, # 시각화에 사용할 데이터프레임
x='title', # x축에는 영화 제목을 표시
y='revenue', # y축에는 영화 수익을 표시
title="흥행 수익 TOP 10 영화", # 차트 제목
color_discrete_sequence=['#C7CEEA'] # 막대 색상 지정 (연보라색 계열)
)
# 5. 그래프 출력 (Jupyter Notebook에서는 자동으로 웹 뷰어가 열림)
fig.show()
💡 보너스 팁 groupby().sum()은 그룹별 합계를 낼 때 자주 쓰이는 대표적인 집계 함수입니다.
reset_index()를 써야 결과가 일반적인 데이터프레임 형태로 바뀌고, 이후 시각화에 쉽게 쓸 수 있어요.
sort_values()로 정렬하면 막대가 높은 순서로 나와서 가독성이 좋아집니다.
color_discrete_sequence는 색을 직접 지정할 수 있는 옵션이며, 리스트 형태로 전달합니다. (색 여러 개 넣으면 범례에 따라 다르게 색칠돼요)
plotly.express는 인터랙티브한 시각화를 손쉽게 만들 수 있어서 matplotlib보다 보기 좋은 결과물이 나오는 경우가 많아요.
title_dic = {'budget':'예산', 'vote_count':'투표수'} # 컬럼명을 한글로 매핑한 딕셔너리
# 'budget'(예산), 'vote_count'(투표수)를 기준으로 각각 TOP10 막대그래프를 그릴 거예요
for y in ['budget', 'vote_count']:
# 1. 'title' 기준으로 그룹화 후, 해당 컬럼(y)의 합계를 구함
# 2. 인덱스를 초기화해 데이터프레임 형태로 만들고
# 3. y 값 기준 내림차순 정렬 후 상위 10개 항목 추출
top = data.groupby('title')[[y]].sum().reset_index().sort_values(y, ascending=False).head(10)
# 4. plotly로 막대그래프 생성
fig = px.bar(
data_frame=top, # 그래프에 쓸 데이터프레임
x='title', # x축에는 영화 제목
y=y, # y축에는 현재 반복 중인 항목 (예산 or 투표수)
title=f"{title_dic[y]} TOP 10 영화", # 제목은 딕셔너리에서 가져온 한글로 표시
color_discrete_sequence=['#AFCBFF'] # 막대 색상 지정 (연한 파란색 계열)
)
# 5. 그래프 출력
fig.show()
top_director =
data # 원본 데이터프레임
.groupby(['director']) # 감독(director)별로 그룹을 짓고
['revenue'].sum() # 각 감독의 총 흥행 수익을 합산한 뒤
.reset_index() # 결과를 표 형태로 보기 좋게 인덱스 초기화하고
.sort_values('revenue', ascending=False) # 수익 기준으로 내림차순 정렬해서
.head(10) # 상위 10명의 감독만 추출해서
#plotly에서 boxplot 만드는 방법
fig = px.box(data_frame = data, y = '', x = 'revenue', hover_name = '')
#data_frame = 데이터 넣고 , y='',x = '' , hover_name='title'
fig.show()
pd.pivot_table(data=data.query('조건'), index='', columns=' ', values=' ', aggfunc=sum, fill_value=0, margins=True)
pd.pivot_table(
data=data.query('조건'), # 1. 피벗테이블을 만들 데이터, 조건에 맞는 행만 선택
index='', # 2. 행 인덱스로 사용할 컬럼명 (피벗테이블의 행 기준)
columns=' ', # 3. 열로 펼칠 컬럼명 (피벗테이블의 열 기준)
values=' ', # 4. 집계할 값이 들어있는 컬럼명
aggfunc=sum, # 5. 값을 집계할 함수 (예: sum, mean, count 등)
fill_value=0, # 6. 결측값(NaN)을 0으로 채움
margins=True # 7. 행과 열의 합계(총합)를 추가해줌 (전체 합계)
)
위치설명예시
data=
피벗테이블 만들 대상 데이터프레임, 필요한 행만 걸러서 사용
data.query('year==2023')
index=
피벗테이블에서 행 방향 기준이 될 컬럼명
'director', 'region'
columns=
피벗테이블에서 열 방향으로 펼칠 컬럼명
'genre', 'month'
values=
집계하려는 대상 컬럼명 (숫자 데이터)
'revenue', 'sales'
aggfunc=
집계함수, 값을 어떻게 요약할지 정함
sum, mean, count
fill_value=
집계 결과에 결측값이 있을 때 대신 채워줄 값
0 (결측값을 0으로 처리)
margins=
행과 열의 합계(총합)를 포함할지 여부 (True/False)
True
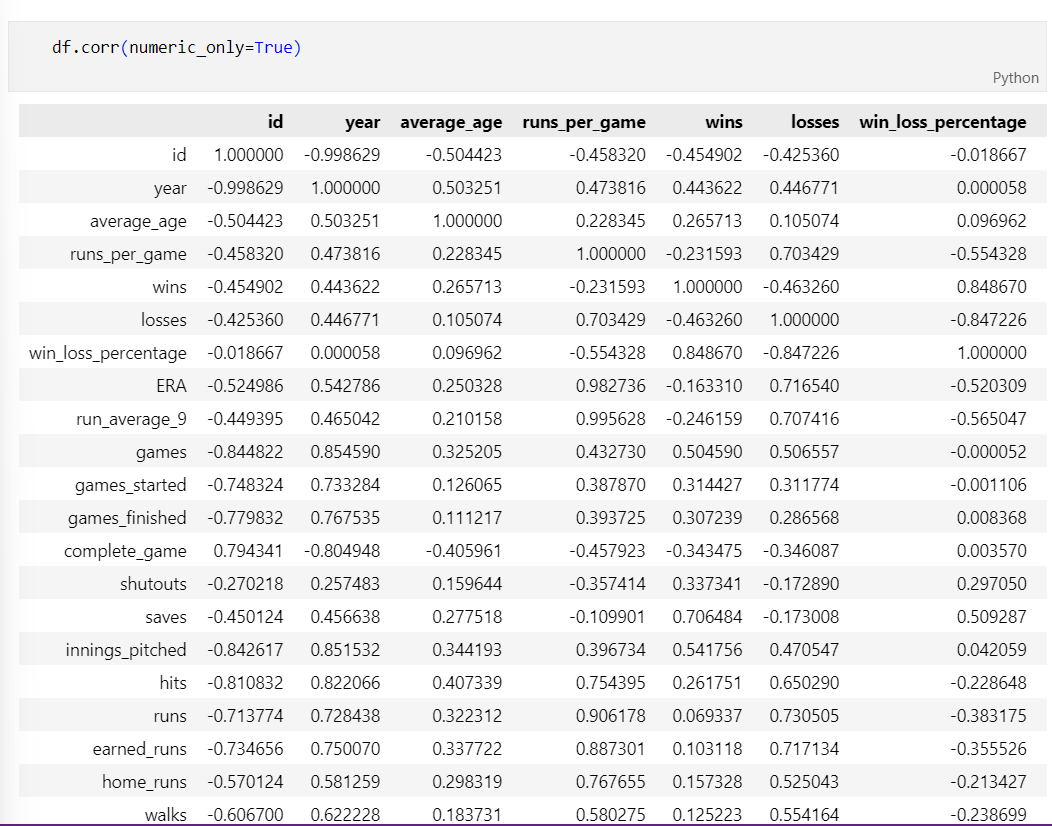
#분석에 사용할 컬럼들 불러오고 .corr() 하면 상관관계가 분석됨
data[['col1','col2','col3','col4']].corr()
#상관분석 결과를 시각화한 히트맵
fig = px.imshow(data[['col1','col2','col3','col4']].corr(), text_auto='.2f', color_continuous_scale='Purp')
fig.show()
# text_auto='.2f 소수점 둘째자리까지
#대각선은 자기자신과의 상관관계로 1로 나오는거임
#trendline이 포함된 scatterplot
for x in ['col1', 'col2', 'col3']: # 1. col1, col2, col3 각각을 x축 변수로 사용해서 반복
fig = px.scatter( # 2. 산점도 그래프 생성
data_frame=data, # 3. 그래프에 사용할 데이터프레임 지정
x=x, # 4. x축 값으로 현재 반복 중인 col1, col2, col3 중 하나
y='col4', # 5. y축 값은 col4
hover_name='title', # 6. 점 위에 마우스 올리면 title 컬럼 값이 보임
size='col4', # 7. 점 크기를 col4 값에 비례해서 조절
color='revenue', # 8. 점 색깔을 revenue 값에 따라 다르게 표현
color_continuous_scale=px.colors.sequential.Sunsetdark, # 9. 점 색깔은 어두운 선셋 색상 그라데이션
width=700, # 10. 그래프 가로 크기 700 픽셀
height=600, # 11. 그래프 세로 크기 600 픽셀
trendline='ols' # 12. x, y 데이터에 대해 선형 회귀 추세선을 그림
)
fig.show() # 13. 그래프 화면에 표시
#bubble chart
data = data.sort_values('col1', ascending=False).head( )
# 'col1' 기준으로 내림차순 정렬 후 상위 일부 행만 선택 (head() 안에 숫자 넣으면 그 개수만큼 가져옴
fig = px.scatter(
data_frame=data, # 2. 그래프에 사용할 데이터프레임 지정
x=' ', # 3. x축에 사용할 컬럼명 (여기에 실제 컬럼명 넣어야 함)
y=' ', # 4. y축에 사용할 컬럼명 (여기에 실제 컬럼명 넣어야 함)
hover_name='title', # 5. 마우스 올리면 영화 제목(title) 보여줌
size='col1', # 6. 버블 크기는 'col1' 값에 비례
color='main_genre', # 7. 버블 색상은 'main_genre'별로 구분
color_discrete_sequence=px.colors.qualitative.Light24, # 8. 색상 팔레트는 Light24로 지정
width=700, # 9. 그래프 가로 크기 700픽셀
height=600 # 10. 그래프 세로 크기 600픽셀
)
fig.show()
🎨 그래프 색상 정리
top = data.groupby('title')['revenue'].sum().reset_index().sort_values('revenue', ascending=False).head(10)
fig = px.bar(
data_frame=top,
x='title',
y='revenue',
title="흥행 수익 TOP 10 영화",
color_discrete_sequence=['#C7CEEA'] # 막대 색상
)
# 배경색 설정은 따로!
fig.update_layout(
paper_bgcolor='white', # 전체 배경
plot_bgcolor='white', # 그래프 영역 배경
yaxis=dict(
showgrid=True,
gridcolor='lightgray'
)
)
fig.show()
#그 외의 취향이던 막대 색상
# pastel = ['#FFB5E8', '#FF9CEE', '#B28DFF', '#DCD3FF', '#AFCBFF', '#B5EAD7', '#C7CEEA']
✨ 복습하면서 헷갈리던 것들
✅ 정리:
title_dic = {'budget':'예산', 'vote_count':'투표수'}
딕셔너리를 쓴 이유
이유설명
보기 좋은 한글 제목으로 바꾸기 위해
plotly title에 사용할 때 직관적 제목을 만들 수 있음
반복문에서 조건별 처리할 때 유용
y 값에 따라 title을 자동으로 다르게 생성 가능
향후 컬럼이 늘어나도 확장성 확보
딕셔너리만 추가하면 코드 전체 수정 없이 반복 가능
🔍 왜 title_dic = {'budget': '예산', 'vote_count': '투표수'}처럼 딕셔너리로 묶었을까?
✅ 1. 반복문에서 컬럼명을 바꿔서 출력하기 위함
for y in ['budget', 'vote_count']: 이렇게 반복하면서
그래프 title에 한글 제목을 넣고 싶잖아요?
그래서 아래처럼 쓸 수 있게 만든 거예요:
title=f"{title_dic[y]} TOP 10 영화"
# y가 'budget'이면 → "예산 TOP 10 영화"
# y가 'vote_count'면 → "투표수 TOP 10 영화"
✅ groupby()는 언제 사용하나요?
groupby()는 데이터를 특정 기준(컬럼 값)에 따라 묶고, 묶인 각 그룹에 대해 합계, 평균, 개수 등의 집계(aggregation) 연산을 하고 싶을 때 사용합니다.
✅ 요약
함수역할
groupby()
특정 기준으로 그룹 묶기 + 집계 연산
reset_index()
그룹 결과의 인덱스를 일반 컬럼으로 변환해서 보기 좋게 만들기
///Q : dropna()함수로 결측치 제거하는데 inplace=True는 왜 사용해? 이게 무슨의미야?
data.dropna(inplace=True)
///✅ inplace=True의 의미
///"결측치를 제거한 결과를 원본 데이터프레임 data에 바로 반영해줘!" 라는 뜻입니다.
✅ inplace=True의 장단점
🔹 장점
메모리 효율성
새로운 복사본을 만들지 않아서 메모리 사용량이 적어요.
특히 데이터가 매우 클 때 유리해요.
코드 간결
별도의 변수 없이 한 줄로 처리할 수 있어서 깔끔해 보여요.
🔸 단점
원본 데이터가 바뀜
한 번 바뀌면 되돌리기 어렵거나 불가능해요 (undo 불가).
실수로 중요한 데이터를 날릴 위험이 있음.
코드의 가독성과 추적성 감소
df = df.dropna()처럼 할당하는 방식은 변화를 명확하게 보여줌.
inplace=True는 묵시적으로 변경되므로 디버깅이나 추적이 어려울 수 있어요.
일부 함수에서는 inplace 옵션이 없어졌거나 사라질 예정
최신 판다스 버전에서는 inplace=True가 비추천(deprecated) 되는 방향으로 가고 있어요.
🚀 처음 보는 함수 정리
ast.literal_eval()은 문자열(String)을 실제 파이썬 객체처럼 안전하게 변환해주는 함수예요. 보통 문자열로 저장된 리스트나 딕셔너리 등을 진짜 리스트나 딕셔너리 객체로 바꿀 때 사용합니다.
x = 10
if x > 5:
print("x는 5보다 큽니다.") # 출력됨
elif x == 5:
print("x는 5입니다.")
else:
print("x는 5보다 작습니다.") // x는 5보다 큽니다.
2. 중첩 조건문
#RuleBase라고 함
x = 13
if x > 10:
if x % 2 == 0: ## 나머지가 0인거 = 짝수인지 확인하려고
print("x는 10보다 크고 짝수입니다.")
else:
print("x는 10보다 크고 홀수입니다.")
else:
print("x는 10 이하입니다.") // x는 10보다 크고 홀수입니다.
3. 조건문
age = 26
is_student = False
if age < 18 or is_student:
print("할인이 적용됩니다.") # 출력됨
else:
print("할인이 적용되지 않습니다.") //할인이 적용되지 않습니다.
(3) 조건문과 자주 사용되는 함수
1.input()
사용자로부터 입력을 받아 조건을 검사할 때 자주 사용됩니다.
age = int(input("나이를 입력하세요: "))
if age >= 18:
print("성인입니다.")
else:
print("미성년자입니다.")
2.len()
문자열이나 리스트의 길이(크)를 조건으로 사용할 수 있습니다.
#다른 예. 리뷰가 50글자 이상인것만
password = "abc12345"
if len(password) >= 6:
print("비밀번호가 유효합니다.")
else:
print("비밀번호는 최소 6자 이상이어야 합니다.")
(4) 비교연산자
조건문에 값을 비교할 때 사용
표현파이썬 코드
a와 b가 같다
a == b
a와 b가 같지 않다
a != b
a가 b보다 작다
a < b
a가 b보다 작거나 같다
a <= b
a가 b보다 크다
a > b
a가 b보다 크거나 같다
a >= b
a = 1
b = 3
print(a == b) # False
print(a != b) # True
print(a < b) # True
print(a <= b) # True
print(a > b) # False
print(a >= b) # False
(5) and, or 연산자
만약에 조건이 2가지 이상인 경우에는?
money = 50000
bus = False #비행기표가 없는거임
# if money >= 50000 and bus:
# print("비행기를 타세요.")
# elif money >= 100000 or bus:
# print("고속버스를 타세요.")
if money>= 50000:
if bus == True:
print('고속버스를 타세요')
elif bus == False:
print('기차를 타세요')
else:
print("걸어가세요")
2. 반복문 (for, while)
: 반복되는 행위를 할 때 사용
# 단 두 줄로 해결이 가능
for i in range(10):
print("meanji is 9월 취뽀", i)
'''
meanji is 9월 취뽀 0
meanji is 9월 취뽀 1
meanji is 9월 취뽀 2
meanji is 9월 취뽀 3
meanji is 9월 취뽀 4
meanji is 9월 취뽀 5
meanji is 9월 취뽀 6
meanji is 9월 취뽀 7
meanji is 9월 취뽀 8
meanji is 9월 취뽀 9
'''
-> 이런 예 사용하면 되게 자기애 강해보이는데 저는 말하는 힘을 믿어요 ✨
for문의 기본 형태
for 변수 in 리스트(또는 튜플, 문자열):
실행할 문장1
(1)for반복문
for반복문은 시퀀스(리스트, 문자열, 튜플 등)의 각 요소를 순차적으로 가져와 작업을 수행합니다.
for 변수 in 시퀀스:
실행할 코드
리스트
fruits = ["apple", "banana", "cherry"]
for fruit in fruits:
print(fruit)
if fruit == 'banana':
print('원숭이')
'''
apple
banana
원숭이
cherry
'''
range()
for i in range(5): # 숫자(0부터 5미만)
print(i)
# for i in range() 이거를 기계적으로 외워자자
'''
0
1
2
3
4
'''
문자열
text = "meanji 취뽀 9월"
for char in text:
print(char)
'''
m
e
a
n
j
i
취
뽀
9
월
'''
(2)while반복문
while문은 조건이 참(True)인 동안 코드를 반복 실행합니다.
while 조건: 실행할 코드
num = 0
while num < 5:
#while True:
#print('실행') # 무한루프에 빠지게 됨 why? 항상 참이니까
num = num + 1
print('num 값: ', num) #num가 5가 되는 순간 멈춤
#while문을 사용할때 조건의 관리가 꼭 필요함
'''
num 값: 1
num 값: 2
num 값: 3
num 값: 4
num 값: 5
'''
num = 0
while num < 5:
#while True:
#print('실행') # 무한루프에 빠지게 됨 why? 항상 참이니까
print('num 값: ', num)
num = num + 1
#이렇게 순서를 바꾸면 01234가 됨
'''
num 값: 0
num 값: 1
num 값: 2
num 값: 3
num 값: 4
'''
for i in range(5):
print(i)
#이게 바로 위에 코드와 같음
'''
0
1
2
3
4
'''
count = 10
while count < 3:
print('이코드는 실행되지 않습니다.') # 아예 실행되지 않음
(3) 반복문에서 자주 사용되는 키워드
1. break
break는 반복문을즉시 종료합니다.
for i in range(5):
if i == 3:
break # 멈춰서 4가 표현이 안되고
print(i)
'''
0
1
2
'''
for i in range(5):
if i == 3:
continue # i=3을 만났을때 여기서 멈춰라는 뜻으로 3에서 넘어가니까 4로 표현되는거임
print(i)
'''
0
1
2
4
'''
2. continue
continue는 현재 반복을 건너뛰고, 다음 반복으로 넘어갑니다.
for i in range(6):
if i == 3:
continue
print(i)
'''
0
1
2
4
5
'''
3. pass
pass는 아무 작업도 하지 않고 반복문을 유지합니다.
for i in range(5):
if i == 3:
pass # todo: 여기서부터
print(i)
'''
0
1
2
3
4
'''
(4) 반복문에서 자주 사용되는 함수
1.range(start, stop, step)
숫자 범위를 생성하며, 시작값(start), 끝값(stop), 증가값(step)을 지정할 수 있습니다.
for i in range(1, 10, 2):
print(i)
'''
1
3
5
7
9
'''
2.enumerate()- 열거하다, 나열하다
리스트나 문자열을 순회하며 인덱스와 값을 동시에 가져옵니다.
fruits = ["apple", "banana", "cherry"]
for fruit in fruits:
print(fruit)
'''
apple
banana
cherry
'''
# 이방식도 많이 사용함 기억해두기
fruits = ["apple", "banana", "cherry"]
for index, fruit in enumerate(fruits): # 몇번째에 들어있는 데이터인지 확인가능함
print(index, fruit)
'''
0 apple
1 banana
2 cherry
'''
3.zip()
여러 시퀀스를 동시에 순회합니다.
names = ["meanji", "Zoa", "쩡유"]
ages = [26, 25, 27]
for name, age in zip(names, ages):
print(f"{name} is {age} years old.")
'''
meanji is 26 years old.
Zoa is 25 years old.
쩡유 is 27 years old.
'''
4.reversed()
리스트나 문자열을 역순으로 순회합니다.
for char in reversed([1,100,3,80,5]): #순서를 보장하는 것이 아님, 단순히 뒤집어주는거임
print(char)
'''
5
80
3
100
1
'''
for char in sorted (reversed([1,100,3,80,5])): #순서를 보장하는 것이 아님, 단순히 뒤집어주는거임
print(char)
'''
1
3
5
80
100
'''
for char in [1,2,3,4,5][::-1]: #reversed 와 동일한거임
print(char)
'''
5
4
3
2
1
'''
# 강사님 Divide and Conquer # 1. 1부터 20까지 나타내자 # 2. 조건을 통해 짝수만 걸러내자
for i in range(1,21): if i % 2 == 0: print('짝수 : ', i )
=> 수업 때 강사님이 알려주신 Divide and Conquer! 며칠 전 정처기 필기 공부할 때도 나왔던 개념이라 두 흐름이 딱 맞아떨어지는 순간, 소소한 재미 포인트임 ♠
-> 여기서 사담을 조금 해보자면 제가 BDA 학회할때도 강사님이 원본 데이터를 그대로 사용하면 나중에 잘못해서 복구하려고 하면 사고다라면서 무조건 데이터를 복사해서 사용하라는 말을 자주들었었는데 복사는 copy() 기억하기
data = [1, 2, 3]
new_data = data
new_data.append(4)
#new data에 4를 추가헀는데 data도 왜 4가 추가냐냐
# 리스트 타입은 메모리도 함게 복사가 되기 때문에 .copy()함수를 쓰는거임
print(new_data, data)
// [1, 2, 3, 4] [1, 2, 3, 4]
data = [1, 2, 3]
new_data = data.copy()
new_data.append(4)
print(data) # [1, 2, 3]
print(new_data) # [1, 2, 3, 4]
# 얕은 복사
# 깊은 복사 ...
4. 딕셔너리형 (Dict)
Dict → 사전
{ 단어 : 뜻 }의 형태
중괄호 안에 키(key)와 벨류(value)로 구성되어 있는 형태
데이터의 빠른 검색, 추가, 삭제를 지원
{Key1:Value1, Key2:Value2, Key3:Value3, ...}
(1) 딕셔너리의 주요 특징
키-값 쌍으로 구성:
데이터는 고유한 키와 값의 쌍으로 저장됩니다.
예:{"name": "Alice", "age": 25}
키는 고유:
키는 중복될 수 없습니다.
변경 가능 (Mutable):
딕셔너리는 생성 후 수정, 추가, 삭제가 가능합니다.
(2) 딕셔너리 생성 및 기본 사용법
딕셔너리 생성
# 빈 딕셔너리 생성
empty_dict = {}
type(empty_dict) //dict
# 값이 있는 딕셔너리 생성
person = {"name": "Alice", "age": 25, "city": "New York"}
print(person) # {'name': 'Alice', 'age': 25, 'city': 'New York'}
#값 추가
person = {"name": "Alice", "age": 25}
# 값 추가
person["city"] = "New York"
print(person) # {'name': 'Alice', 'age': 25, 'city': 'New York'}
# 값 수정
person["age"] = 33
print(person) # {'name': 'Alice', 'age': 33, 'city': 'New York'}
딕셔너리 값 삭제
person = {"name": "Alice", "age": 25, "city": "New York"}
# 특정 키 삭제 (del: 예약어)
del person["city"]
print(person) # {'name': 'Alice', 'age': 25}
# 모든 키-값 삭제
person.clear() #기존에 있던 data는 다 날아가고 빈 딕셔너리가 출력됨
print(person) # {}
# type(x)랑 print(type(x))랑 어떻게 차이가 나나요?
#print(): 괄호 안의 변수의 결과를 보여줌
print(type(1)) # 파이썬이 알려주는거
print(type(1.0)) #float # print() 함수를 이용해주면 결과값을 모두 알려줌
문자형 (String)
문자형(String)은 문자의 집합으로 이루어진 데이터 타입입니다.
텍스트 데이터를 다룰 때 사용되며, 작은 따옴표(') 또는 큰 따옴표(")로 묶어서 표현합니다.
(1) 문자형 기본 사용법
문자형 생성
# 작은 따옴표와 큰 따옴표 모두 사용 가능
text1 = 'Hello'
text2 = "World"
text1, text2 # Hello World
# 올바른 예시
my_list = [1, 2, 3, 4]
# 잘못된 예시 ❌ (소괄호는 튜플, 중괄호는 딕셔너리/집합)
my_tuple = (1, 2, 3) # 튜플
my_dict = {1: 'a'} # 딕셔너리
my_set = {1, 2, 3} # 집합
리스트는 순서가 있고, 값 변경이 가능합니다! (가장 많이 쓰이는 자료형 중 하나예요)
뒤에서 자료형이 나올때마다 알려줄테지만
처음 파이썬배울때 괄호 대괄호 소괄호 중괄호 너무 헷갈렸고 지금도 자신없지만.....
기억하기 리스트 대괄호
문자열 포함 여부:in,not in
특정 문자열이 포함되어 있는지 확인합니다.
data = "(주)화주유소, 주식회사 화주유소"
"(주)" in data or "주식회사" in data
#or조건을 사용해서 (주) 포함되거나 주식회사라고 포함된다면 이건 주식회사라고 하는거
(4) 문자열 포맷팅
파이썬에서는 문자열을 동적으로 구성하기 위한 다양한 포맷팅 방법을 제공합니다.
name = 'meanji'
age = '26'
message = 'My name is {} and I am {} years old.'.format(name,age)
print(message)
#이게 중괄호가 많이 나오면 실수하기 쉽기 때문에 f-string을 사용하면 구조가 문자열 포맷팅보다 안정적임
name = 'meanji'
age = '26'
message = f'My name is {name} and I am {age} years old.'
print(message)
# 카카오 알림메시지를 보낼때 f-string을 많이 사용함
name = "김민지만지망디"
event = '쌍쌍바모임'
date = "5월 16일(금) 오후 2시"
message = "{}님, '{}'에 신청이 완료되었습니다.\n📅 일시: {}".format(name, event, date)
print(message)
//김민지만지망디님, '쌍쌍바모임'에 신청이 완료되었습니다.
//📅 일시: 5월 16일(금) 오후 2시